First Call I Made When I First Heard About “Gen5 Fibre Channel”
June 12, 2013 Leave a comment

Where servers, storage and networking combine to form Voltron.
April 18, 2013 4 Comments
In case you haven’t heard, Brocade is rebranding their 16 Gbit Fibre Channel offerings as Generation 5 Fibre Channel. Upcoming 32 Gbit Fibre Channel will also be called “Gen 6 Fibre Channel”. Seriously.

Cisco’s J Metz responded, and then Brocade responded to that. And a full-on storage smack-down started.
And you thought storage was boring.
It’s exciting!
Brocade is trying to de-emphasize speed as the primary differentiator to a specific Fibre Channel technology, which is weird, since that’s by far the primary differentiator between the generations. This strategy has two major flaws as I see it:
Flaw #1: They’re trying to make it look like you can solve a problem that you really can’t with 16 Gbit FC. Whether you emphasize speed or other technological aspects of 16 Gbit Fibre Channel, 16 Gbit/Gen 5 isn’t going to solve any of the major problems that currently exists in the data center or storage for that matter, at least for the vast majority of Fibre Channel installations. Virtualization workloads, databases, and especially VDI are thrashing our storage systems. However, generally speaking (always exceptions) we’re not saturating the physical links. Not on the storage array links, not on the ISLs, and definitely not on the server FC links. Primarily the issue we face in the data center are limitations are IOPS.

The latency differences between Fibre Channel speeds is insignificant compared to the latencies introduced by overwhelmed storage arrays
Or, no wait, guys. Guys. Guys. Check out the… choke point.
16 Gbit can give us more throughput, but so can aggregating more 8 Gbit links, especially since single flows/transactions/file operations aren’t likely to eat up more than 8 Gbit (or even a fraction of that). There’s a lower serialization delay and lower latency associated with 16 Gbit, but that’s minuscule compared to the latencies introduced by storage systems. The vast majority of workloads aren’t likely to see significant benefit moving to 16 Gbit. So for right now, those in the storage world are concentrating on the arrays, and not the fabric. And that’s where they should be concentrating.
From one of Brocade’s posts, they mention this of Gen5 Fibre Channel:
“It’s about the innovative technology and unique capabilities that solve customer challenges.”
Fibre Channel is great. And Brocade has a great Fibre Channel offering. For the most part, better than Cisco. But there isn’t any innovation in this generation of Fibre Channel other than the speed increase. I’m kind of surprised Brocade didn’t call it something like “CloudFC”. This reeks of cloud washing, without the use of the word cloud. I mean, it’s Fibre Channel. It’s reliable, it’s simple to implement, best practices are easily understood, and it’s not terribly sexy, and calling it Gen5 isn’t going to change any of that.
Flaw #2: It creates market confusion.
Cisco doesn’t have any 16 Gbit Fibre Channel offerings (they’re pushing for FCoE, which is another issue). And when they do get 16 Gbit, they’re probably not going to call it Gen 5. Nor is most of the other Fibre Channel vendors, such as Emulex, Qlogic, NetApp, EMC, etc. HP and Dell have somewhat gone with it, but they kind of have to since they sell re-branded Brocade kit (it’s worth noting that even HP’s material is peppered with the words “16 Gbit”). So having another term is going to cause a lot of unnecessary conversations.
Here’s how I suspect a lot of Brocade conversations with new and existing customers will go:
“We recommend our Gen 5 products”
“What’s Gen 5?”
“It’s 16 Gbit Fibre Channel”
“OK, why didn’t you just say that?”
This is what’s happened in the load balancing world. A little over six years ago, Gartner and marketing departments tried to rename load balancers to “Application Delivery Controllers”, or ADCs for short. No one outside of marketing knows that the hell an ADC is. But anyone who’s worked in a data center knows what a load balancer is. They’re the same thing, and I’ve had to have a lot of unnecessary conversations since. Because of this, I’m particularly sensitive to changing the name of something that everyone already knows of for no good frickin’ reason.
Where does that leave Fibre Channel? For the challenges that most organizations are facing in the data center, an upgrade to 16 Gbit FC would be a waste of money. Sure, if given the choice between 8 and 16 Gbit FC, I’d pick 16. But there’s no compelling reason for the vast majority of existing workloads to convert to 16 Gbit FC. It just doesn’t solve any of the problems that we’re having. If you’re building a new fabric, then yes, absolutely look at 16 Gbit. It’s better to have more than to have less of course, but the benefits of 16 Gbit probably won’t be felt for a few years in terms of throughput. It’s just not a pain point right now, but it will be in the future.
In fact, looking at most of the offerings from the various storage vendors (EMC, NetApp, etc.), they’re mostly content to continue to offer 8 Gbit as their maximum speed. The same goes for server vendors (though there are 16 Gbit HBAs now available). I teach Cisco UCS, and most Cisco UCS installations plug into Brocade fabrics. Cisco UCS Fibre Channel ports only operates at a maximum of 8 Gbit, and I’ve never heard a complaint regarding the lack of 16 Gbit. Especially since you can use multiple 8 Gbit uplinks to scale connectivity.
April 1, 2013 5 Comments
In the world of Ethernet, jumbo frames (technically any Ethernet frame larger than 1,500 bytes) is often a recommendation for certain workloads, such as iSCSI, vMotion, backups, basically anything that doesn’t communicate with the Internet because of MTU issues. And in fact, MTU issues is one of the biggest hurdles with Ethernet jumbo frames, since every device on a given LAN must have the correct MTU size set if you want them to successfully communicate with each other.
What’s less known is that you can also enable jumbo frames for Fibre Channel as well, and that doing so can have dramatic benefits with certain workloads. Best of all, since SANs are typically smaller in scope, ensuring every device has jumbo frames enabled is much easier.
Fibre Channel Frames
Fibre Channel frames typically have a maximum payload size of 2112, and with with headers makes the MTU 2148 bytes. However you can increase the payload up to 9000 bytes, and with headers that 9036 bytes. You can play with the payload size if you like, but just to make it easier I either do regular MTU (2148 bytes) or I do the max for most switches (9036). My perfunctory tests don’t seem to indicate much benefit with anything in between.
Supported
Of course, not all Fibre Channel devices can handle jumbo frames. It’s part of the T10 standard though since 2005, so most modern devices (anything capable of 4 Gbit or more, for the most part). This includes switches from Cisco and Brocade, as well as HBAs from Qlogic and Emulex.
Configuration
The way you configure jumbo frames of course varies, and of course I don’t have lots of different types of equipment, so I’m just going to demonstrate on an MDS that I have access to.
Note: Do not do anything in a production environment until you’ve tested it in a dev environment. If you do otherwise, you’re an idiot.
If you go into an interface configuration, you’ll probably notice there’s no MTU option. That’s because we’re dealing with a fabric here, and the MTU is set per VSAN, not per port. Multi-VSAN ISLs (TE_Ports) will do multiple MTUs without any problem. Keep in mind, changing MTUs on an MDS/Nexus requires a reboot (I think mostly because the N_Ports need to do a new FLOGI). I’m not sure about Brocade, however.
Switch#1# config t Enter configuration commands, one per line. End with CNTL/Z. Switch#1(config)# mtu size vsan 10 9036 VSAN 10 MTU changed. Reboot required. Switch#1(config)# mtu size vsan 20 9036 VSAN 20 MTU changed. Reboot required. Switch#1(config)# exit Switch#1# reload
Right now the maximum MTU size per the standard is 9036 bytes, though it depends on the vendor. Brocade, with it’s Gen 6 FC (32 Gbit) is proposing a maximum MTU size of around 15,000 bytes, though it’s not set in stone yet. It’ll be interesting to see how this all plays out, that’s for sure.
Testing
How well does it work? I haven’t tested it for VDI or otherwise high-IOPs environments, but my suspicion is that it’s not going to help. Given the longer serialization, it would actually probably hurt performance. For other workloads, such as backups, they can make a dramatic difference. As a test, I did a couple of vSphere Storage vMotions, and I was surprised to see how fast it went.
Hosts were B200 M2 blades, with 96 GByte of RAM running EXI 5.1. Fibre Channel cards were Cisco M81KR, configured for 9036 byte frames (9,100 bytes on the FCoE interface since VICs are CNAs, so had to add several dozen bytes for FCoE headers/VNTAG, etc.). The FC switch was actually a Cisco 6248 Fabric Interconnect set for Fibre Channel switching mode. All tests were done on the A fabric. I initiated Storage vMotions on a 2 TB VMDK file. The VMDK wasn’t receiving an active workload, so it was mostly idle. I ran the test 20 times for each size, and averaged the results.
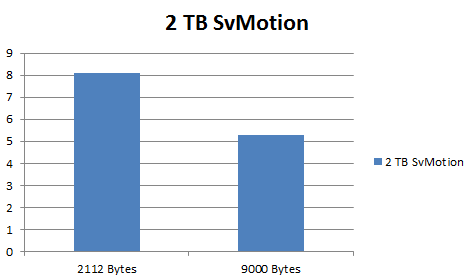
It’s just a quick and dirty test on a barely-active VMDK, but you can see that with 9000 Byte FC frames, it’s almost twice as fast.
May 21, 2012 2 Comments
In a recent post, I took a look at the Fibre Channel subjects of NPIV and NPV, both topics covered in the CCIE Data Center written exam (currently in beta, take yours now, $50!). The post generated a lot of comments. I mean, a lot. Over 50 so far (and still going). An epic battle (although very unInternet-like in that it was very civil and respectful) brewed over how Fibre Channel compares to Ethernet/IP. The comments look like the aftermath of the battle of Wolf 359.

Captain, the analogy regarding squirrels and time travel didn’t survive
One camp, lead by Erik Smith from EMC (who co-wrote the best Fibre Channel book I’ve seen so far, and it’s free), compares the WWPNs to IP addresses, and FCIDs to MAC addresses. Some others, such as Ivan Pepelnjak and myself, compare WWPNs to MAC addresses, and FCIDs to IP addresses. There were many points and counter-points. Valid arguments were made supporting each position. Eventually, people agreed to disagree. So which one is right? They both are.
Wait, what? Two sides can’t be right, not on the Internet!
When comparing Fibre Channel to Ethernet/IP, it’s important to remember that they are different. In fact, significantly different. The only purpose for relating Fibre Channel to Ethernet/IP is for the purpose of relating those who are familiar with Ethernet/IP to the world of Fibre Channel. Many (most? all?) people learn by building associations with known subjects (in our case Ethernet/IP) to lesser known (in this case Fibre Channel) subjects.
Of course, any association includes includes its inherent inaccuracies. We purposefully sacrifice some accuracy in order to attain relatability. Specific details and inaccuracies are glossed over. To some, introducing any inaccuracy is sacrilege. To me, it’s being overly pedantic. Pedantic details are for the expert level. Using pedantic facts as an admonishment of an analogy misses the point entirely. With any analogy, there will always be inaccuracies, and there will always be many analogies to be made.
Personally, I still prefer the WWPN ~= MAC/FC_ID ~= IP approach, and will continue to use it when I teach. But the other approach I believe is completely valid as well. At that point, it’s just a matter of preference. Both roads lead to the same destination, and that is what’s really important.
Learning always happens in layers. Coat after coat is applied, increasing in accuracy and pedantic details as you go along. Analogies is a very useful and effective tool to learn any subject.
May 8, 2012 70 Comments
The CCIE Data Center blueprint makes mention of NPV and NPIV, and Cisco UCS also makes heavy use of both topics, topics that many may be unfamiliar with most. This post (part of my CCIE Data Center prep series) will explain what they do, and how they’re different.
(Another great post on NPV/NPIV is from Scott Lowe, and can be found here. This is a slightly different approach to the same information.)
NPIV and NPV are among the two most ill-named of acronyms I’ve come across in IT, especially since they sound very similar, yet do two fairly different things. NPIV is an industry-wide term and is short for N_Port ID Virtualization, and NPV is a Cisco-specific term, and is short for N_Port Virtualization. Huh? Yeah, not only do they sound similar, but the names give very little indication as to what they do.
First, let’s talk about NPIV. To understand NPIV, we need to look at what happens in a traditional Fibre Channel environment.
When a host plugs into a Fibre Channel switch, the host end is called an N_Port (Node Port), and the FC switch’s interface is called an F_Port (Fabric Port). The host has what’s known as a WWPN (World Wide Port Name, or pWWN), which is a 64-bit globally unique label very similar to a MAC address.
However, when a Fibre Channel host sends a Fibre Channel frame, that WWPN is no where in the header. Instead, the host does a Fabric Login, and obtains an FCID (somewhat analagous to an IP addres). The FCID is a 24-bit number, and when FC frames are sent in Fibre Channel, the FCID is what goes into the source and destination fields of the header.

Note that the first byte (08) of the FCID is the same domain ID as the FC switch that serviced the host’s FLOGI.
In regular Fibre Channel operations, only one FCID is given per physical port. That’s it. It’s a 1 to 1 relationship.
But what if you have an ESXi host, for example, with virtual fibre channel interfaces. For those virtual fibre channel interfaces to complete a fabric login (FLOGI), they’ll need their own FCIDs. Or, what if you don’t want to have a Fibre Channel switch (such as an edge or blade FC switch) go full Fibre Channel switch?
NPIV lets a FC switch give out multiple FCIDs on a single port. Simple as that.

The magic of NPIV: One F_Port gives out multiple FCIDs on (0x070100 to the ESXi host and 0x070200 and 0x070300 to the virtual machines)
NPV is typically used on edge devices, such as a ToR Fibre Channel switch or a FC switch installed in a blade chassis/infrastruture. What does it do? I’m gonna lay some Star Trek on you.
NPV is a clocking device for a Fibre Chanel switch.

Wait, did you just compare Fibre Channel to a Sci-Fi technology?
How is NPV like a cloaking device? Essentially, an NPV enabled FC switch is hidden from the Fibre Channel fabric.
When a Fibre Channel switch joins a fabric, it’s assigned a Domain_ID, and participates in a number of fabric services. With this comes a bit of baggage, however. See, Fibre Channel isn’t just like Ethernet. A more accurate analogue to Fibre Channel would be Ethernet plus TCP/IP, plus DHCP, distributed 802.1X, etc. Lots of stuff is going on.
And partly because of that, switches from various vendors tend not to get a long, at least without enabling some sort of Interopability Mode. Without interopability mode, you can’t plug a Cisco MDS FC switch into say, a Brocade FC switch. And if you do use interopability mode and two different vendors in the same fabric, there are usually limitations imposed on both switches. Because of that, not many people build multi-vendor fabrics.
Easy enough. But what if you have a Cisco UCS deployment, or some other blade system, and your Fibre Channel switches from Brocade? As much as your Cisco rep would love to sell you a brand new MDS-based fabric, there’s a much easier way.
Engage the cloaking device.
(Note: NPV is a Cisco-specific term, while other vendors have NPV functionality but call it something else, like Brocade’s Access Gateway.) A switch in NPV mode is invisible to the Fibre Channel fabric. It doesn’t participate in fabric services, doesn’t get a domain ID, doesn’t do fabric logins or assign FCIDs. For all intents and purposes, it’s invisible to the fabric, i.e. cloaked. This simplifies deployments, saves on domain IDs, and lets you plug switches from one vendor into a switch of another vendor. Plug a Cisco UCS Fabric Interconnect into a Brocade FC switch? No problem. NPV. Got a Qlogic blade FC switch plugging into a Cisco MDS? No problem, run NPV on the Qlogic blade FC switch (and NPIV on the MDS).

The hosts perform fabric logins just like they normally would, but the NPV/cloaked switch passes FLOGIs up to the NPIV enabled port on the upstream switch. The FCID of the devices bears the the Domain ID of the upstream switch (and appears directly attached to the upstream switch).
The NPV enabled switch just proxies the FLOGIs up to the upstream switch. No fuss, no muss. Different vendors can interoperate, we save domain IDs, and it’s typically easier to administer.
TL;DR: NPIV allows multiple FLOGIs (and multiple FCIDs issued) from a single port. NPV hides the FC switch from the fabric.
April 1, 2012 4 Comments
There’s a common misconception about Fibre Channel, in that it only operates in a lossless mode. While it’s true that for many applications, Fibre Channel is used in a totally lossless way (commonly through buffer to buffer credits and other less used mechanisms). But there is a class of service supported by most Fibre Channel switch vendors and HBAs that does allow for less care (and thus dropping) of Fibre Channel frames: Best Effort (Class 9).
There are several classes of service in Fibre Channel. All but one of them is lossless. Most of the time, Fibre Channel runs in Class 3, which provides losslessness through a buffer credit mechanism. Here are all the Fibre Channel classes of service, (although typically just Class 3, 6, and 9 are supported in modern switches):
Fibre Channel is usually lossless because it’s running the SCSI protocol as the upper layer protocol, and there’s a widely (but somewhat erroneous) belief that SCSI doesn’t tolerate lost commands well. For some applications, that’s true, loss of a SCSI command is bad. If you’re running a financial institution with an Oracle database or FICON connected mainframe to keep track of financial records, then yes, you’re going to want to run a supported lossless method (typically Class 3).
But there are situations where running Class 9 best effort Fibre Channel may be beneficial. If you’re running a web site with a message board or a Windows server, your SCSI requirements aren’t all that tough. You can lose a SCSI command here or there, and either the application will recover (loading up Battlefield 3) or you just don’t care (troll on a message board).
Class 9 is relatively new, only having been ratified by the T11 working group (under P9FOS committee) in 2005. However since it was designed specifically for existing hardware, only a software update is needed to support it, so most switch and HBA firmware from the major vendors (Cisco, Brocade, Emulex, QLogic, etc.) support it. The idea for a class of lossfull service was in fact inspired by Ethernet.

Fibre Channel, where did you learn to drop frames?
From you, Ethernet, all right? I learned it from watching you!
Turning on Fibre Channel Class 9 (FC_BE, Best Effort) is easy on a Cisco MDS:
switch# conf t switch(config)# no system default switch(config)# switchport mode F switch(config)# switchport class 9 switch(config)# switchport buffer wred
The mode F turns the port into an F_Port (for an N_Port to plug into), and class 9 makes it class 9. The last command is an important one that most people forget: Turning on WRED (Weighted Random Early Detection). This is a buffer management mechanism that drops frames randomly when a buffer gets close to full. You might be familiar with this mechanism in Ethernet ports as a method to prevent tail drop (leaky bucket) so that TCP performance doesn’t suffer. We’re obviously not running TCP (although you could with IPFC), but tail drop is still bad performance-wise with SCSI.
So why would you wanto to turn on Class 9? Performance mostly. You can get a serious case of HoL (Head of Line) blocking because of congestion somewhere else in the Fabric. Class 9 enables the FIWDI (Fuck It, We’ll Drop It) mechanism when congestion occurs in a fabric.

Congestion on the fabric? Fuck it, we’ll drop the frame!
Note: So as not to pollute Google results, this was of course an April Fools joke. There’s not way anyone who loves Fibre Channel would allow lossfullness.
February 10, 2012 12 Comments
I saw a tweet recently from storage and virtualization expert Stu Miniman regarding Emulex announcing copper 10GBase-T Converged Network Adapters, running 10 Gigabit Ethernet over copper (specifically Cat 6a cable).
I recalled a comment I heard Greg Ferro made on a packet pushers episode (and subsequent blog post) about copper not being reliable enough for storage, with the specific issue being the bit error rate (BER), how how many errors the standard (FC, Ethernet, etc.) will allow over a physical medium. As we’ve talked about before, networking people tend to be a little more devil-may-care about their bits, where as storage folks get all anal rententive chef about their bits.
For 1 Gigabit Ethernet over copper (802.3ab/1000Base-T), the standard calls for a goal BER of less than 10-10, or one wrong bit in every 10,000,000,000 bits. Which incidentally, is one error every second for a line rate 10 Gigabit Ethernet. For Gigabit, that’s on error every 10 seconds, or 6 per minute.
Fibre Channel has a BER goal of less than 10-12, or on error in every 1,000,000,000,000 bits. That would be about 2 errors a minute with 10 Gigabit Ethernet. That’s also 100 times less error-prone than Ethernet, which if you think about it, is a lot.
To give a little scale, that’s like comparing Barney Fife from The Andy Griffith show’s bad assery to Jason Statham’s character in.. well any movie he’s ever been in.

Holy shit, is he fighting… truancy?

Barney Fife, the 10-10 error rate of law enforcement. Wait… Wow, did I really just say that?
So given how fastidious about their storage networks storage folks can be, it’s understandable that storage administrator wouldn’t want their precious SCSI commands running over a network that’s 100 times less reliable than Fibre Channel.
However, while the Gigabit Ethernet standard has a BER target of less than 10-10, the 802.3an standard for 10 Gigabit Ethernet over copper (10GBaseT) has a BER goal of less than 10-12, which is in line with Fibre Channel’s goal. So is 10 Gigabit Ethernet over Cat 6A good enough for storage (specifically FCoE)? Sounds like it.
But the discussion also got me thinking, how close do we get to 10-10 as an error rate in Gigabit Ethernet? I just checked all the physical interfaces in my data center (laundry room), and every error counter is zero (presumably most errors would show up as CRC errors). And all it takes to hit 1010 bits is 1.25 Gigabytes of data transfer, and I do that when I download a movie off of iTunes. So I know I’ve put dozens of gigs through my desktop since it was last rebooted, and nary an error. And my cabling isn’t exactly data center standard. One cable I use came with a cheap wireless access point I got a while ago. It makes me curious to what the actual BER is in reality with decent cables that don’t come close to 100 meters.
Of course, there’s still the power consumption issues and other drawbacks that Greg mentioned when compared to fiber (or coax). However, it’ll be good to have another option. There are some shops that won’t likely ever have fiber optics deployed.
November 3, 2011 13 Comments
One recurring theme from virtually every one of the Network Field Day 2 vendor presentations last week (as well as the OpenFlow symposium) was affectionately referred to as “The Problem”.
It was a theme because, as vendor after vendor gave a presentation, they essentially said the same thing when describing the problem they were going to solve. For us the delegates/bloggers, it quickly went from the problem to “The Problem”. We’d heard it over and over again so often that during the (5th?) iteration of the same problem we all started laughing like a group of Beavis and Butt-Heads during a vendor’s presentation, and we had to apologize profusely (it wasn’t their fault, after all).
 Huh huhuhuhuhuh… he said “scalability issues”
Huh huhuhuhuhuh… he said “scalability issues”
In fact, I created a simple diagram with some crayons brought by another delegate to save everyone some time.
 Hello my name is Simon, and I like to do draw-wrings
Hello my name is Simon, and I like to do draw-wrings
But with The Problem on repeat it became very clear that the majority of networking companies are all tackling the very same Problem. And imagine the VC funding that’s chasing the solution as well.
So what is “The Problem”? It’s multi-faceted and interrelated set of issues:
The biggest problem of them all was caused by the rise of virtualization. Virtualization has disrupted much of the server world, but the impact that it’s had on the network is arguably orders of magnitude greater. Virtualization wants big, flat networks, just when we got to the point where we could route Layer 3 as fast as we could switch Layer 2. We’d just gotten to the point where we could get our networks small.
And it’s not just virtualization in general, much of its impact is the very simple act of vMotion. VMs want to keep their IPs the same when they move, so now we have to bend over backwards to get it done. Add to the the vSwitch sitting inside the hypervisor, and the limited functionality of that switch (and who the hell manages it anyway? Server team? Network team?)
If you’re a single enterprise running your own network, chances are 4000+ VLANs are sufficient (or perhaps not). In multi-tenant environments with thousands of customers, 4000+ VLANs quickly becomes a problem. There is a need for some type of VLAN multiplier, something like QinQ or VXLAN, which gives us 4096 times 4096 VLANs (16 million or so).
One of my first introductions to networking was accidentally causing a bridging loop on a 10 megabit Ethernet switch (with a 100 Mbit uplink) as a green Solaris admin. I’d accidentally double-connected a hub, and I noticed the utilization LED on the switch went from 0% to 100% when I plugged a certain cable in. I entertained myself with plugging in and unplugging the port to watch the utilization LED flucutate (that is, until the network admin stormed in and asked what the hell was going on with his network).
And thus began my love affair with bridging loops. After the Brocade presentation where we built a TRILL-based Fabric very quickly, with active-active uplinks and nary a port in blocking mode, Ethan Banks became a convert to my anti-spanning tree cause.
OpenFlow offers an even more comprehensive (and potentially more impressive) solution as well. More on that later.
The current method by which MAC addresses are learned in modern switches causes two problems: Only one viable path can be allowed at a time (only way to prevent loops is to prevent multiple paths by blocking ports), and large Layer 2 networks involve so many MAC addresses that it doesn’t scale.
From QFabric, to TRILL, to OpenFlow (to half a dozen other solutions), Layer 2 transforms into something Layer 3-like. MAC addresses are routed just like IP addresses, and the MAC address becomes just another tuple (another recurring word) for a frame/packet/segment traveling from one end of your datacenter to another. In the simplest solution (probably TRILL?) MAC learning is done at the edge.
Automation is coming, and in a big way. Whether it’s a centralized controller environment, or magical software powered by unicorn tears, vendors are chomping at the bit to provide some sort of automation for all the shit we need to do in the network and server world. While certainly welcomed, it’s a tough nut to crack (as I’ve mentioned before in Automation Conundrum).
Data center automation is a little bit like the Gom Jabbar. They tried and failed you ask? They tried and died.
 “What’s in the box?”
“What’s in the box?”
“Pain. And an EULA that you must agree to. Also, man-years of customization. So yeah, pain.”
It’s quite clear that Ethernet has won the networking wars. Not that this is any news to anyone who’s worked in a data center for the past ten years, but it has struck me that no other technology has been so much as even mentioned as one for the future. Bob Metcalfe had the prophetic quote that Stephen Foskett likes to use: “I don’t know what will come after Ethernet, but it will be called Ethernet.”
But there are limitations (Layer 2 MAC learning, virtualization, VLANs, storage) that need to be addressed for it to become what comes after Ethernet. Fibre Channel is holding ground, but isn’t exactly expanding, and some crazy bastards are trying to merge the two.
Most people agree that storage is going to end up on our network (converged networking), but there are as many opinions on how to achieve this network/storage convergence as there are nerd and pop culture reference in my blog posts. Some companies are pro-iSCSI, others pro FC/NFS, and some like Greg Ferro have the purest of all hate: He hates SCSI.
 “Yo iSCSI, I’m really happy for you and imma let you finish, but Fibre Channel is the best storage protocol of all time”
“Yo iSCSI, I’m really happy for you and imma let you finish, but Fibre Channel is the best storage protocol of all time”
So that’s “The Problem”. And for the most part, the articles on Networking Field Day, and the solutions the vendors propose will be framed around The Problem.
September 14, 2011 17 Comments
Fibre Channel? Meet Ethernet. Ethernet? Meet Fibre Channel. Hilarity ensues.
The entire thesis of this blog is that the traditional data center silos are collapsing. We are witnessing the rapid convergence of networking, storage, virtualization, server administration, security, and who knows what else. It’s becoming more and more difficult to be “just a networking/server/storage/etc person”.
One of the byproducts of this is the often hilarious fallout from conflicting interests, philosophies, and mentalities. And perhaps the greatest friction comes from the conflict of storage and network administrators. They are the odd couple of the data center.
 Storage and Networking: The Odd Couple
Storage and Networking: The Odd Couple
Ethernet is the messy roomate. Ethernet just throws its shit all over the place, dirty clothes never end up in the hamper, and I think you can figure out Ethernet’s policy on dish washing. It’s disorganized and loses stuff all the time. Overflow a receive buffer? No problem. Hey, Ethernet, why’d you drop that frame? Oh, I dunno, because WRED, that’s why.
 WRED is the Yosamite Sam of Networking
WRED is the Yosamite Sam of Networking
But Ethernet is also really flexible, and compared to Fibre Channel (and virtually all other networking technologies) inexpensive. Ethernet can be messy, because it either relies on higher protocols to handle dropped frames (TCP) or it just doesn’t care (UDP).
Fibre Channel, on the other hand, is the anal-retentive network: A place for everything, and everything in its place. Fibre Channel never loses anything, and keeps track of it all.

There now, we’re just going to put this frame right here in this reserved buffer space.
The overall philosophies are vastly different between the two. Ethernet (and TCP/IP on top of it) is meant to be flexible, mostly reliable, and lossy. You’ll probably get the Layer 2 frames and Layer 3 packets from one destination to another, but there’s no gurantee. Fibre Channel is meant to be inflexible (compared with Ethernet), absolutely reliable, and loss-less.
Fibre channel and Ethernet have a very different set of philosophies in terms of building out a network. For instance, in Ethernet networks, we cross-connect the hell out of everything. Network administrators haven’t met two switches they didn’t want to cross connect.
Did I miss a way to cross-connect? Because I totally have more cables
It’s just one big cloud to Ethernet administrators. For Fibre Channel administrators, one “SAN” is abomination. There are always two, air gap separated, completely separate fabrics.

The greatest SAN diagram ever created
The Fibre Channel host at the bottom is connected into two separate, Gandalf-separated, non-overlapping Fibre Channel fabrics. This allows the host two independent paths to get to the same storage array for full redundancy. You’ll note that the Fibre Channel switches on both sides have two links from switch to switch in the same fabric. Guess what? They’re both active. Multi-pathing in Fibre Channel is allowed through use of the FSPF protocol (Fabric Shortest Path First). Fibre Channel switch to Fibre Channel switch is, what we would consider in the Ethernet world, layer 3 routed. It’s enough to give one multi-path envy.
One of the common ways (although by no means the only way) that an Ethernet frame could meet an unfortunate demise is through tail drop or WRED of a receive buffer. As a buffer in Ethernet gets full, WRED or a similar technology will typically start to randomly drop frames. As the buffer gets closer to full, the faster the frames are randomly dropped. WRED prevents tail drop, which is bad for TCP, but dropping frames when the buffer gets closer to full.
Essentially, an Ethernet buffer is a bit like Thunderdome: Many frames enter, not all frames leave. With Ethernet, if you tried to do full line rate of two 10 Gbit links through a single 10 Gbit choke point, half the frames would be dropped.
To a Fibre Channel adminsitrator, this is barbaric. Fibre Channel is much more civilized with the use of Buffer-to-Buffer (B2B) credits. Before a Fibre Channel frame is sent from one port to another, the sending port reserves space on the receiving port’s buffer. A Fibre Channel frame won’t get sent unless there’s guaranteed space at the receiving end. This insures that no matter how much you over subscribe a port, no frames will get lost. Also, when a Fibre Channel frame meets another Fibre Channel frame in a buffer, it asks for the Grey Poupon.
With Fibre Channel, if you tried to push two 8 Gbit links through a single 8 Gbit choke point, no frames would be lost, and each 8 Gbit port would end up throttled back to roughly 4 Gbit through the use of B2B credits.
Why is Fibre Channel so anal retentive? Because SCSI, that’s why. SCSI is the protocol that most enterprise servers use to communicate with storage. (I mean, there’s also SATA, but SCSI makes fun of SATA behind SATA’s back.) Fibre Channel runs the Fibre Channel Protocol, which encapsulates SCSI commands onto Fibre Channel fames (as odd as it sounds, Fibre Channel and Fibre Channel Protocol are two distinct technologies). Fibre Channel is essentially SCSI over Fibre Channel.
SCSI doesn’t take kindly to dropped commands. It’s a bit of a misconception that SCSI can’t tolerate a lost command. It can, it just takes a long time to recover (relatively speaking). I’ve seen plenty of SCSI errors, and they’ll slow a system down to a crawl. So it’s best not to lose any SCSI commands.
We used to have separate storage and networking environments. Now we’re seeing an explosion of convergence: Putting data and storage onto the same (Ethernet) wire.
Ethernet is the obvious choice, because it’s the most popular networking technology. Port per port, Ethernet is the most inexpensive, most flexible, most widely deployed networking technology around. It has slated the FIDDI dragon, the token ring revolution, and now it has its sights on the Fibre Channel Jabberwocky.
The current two competing technologies for this convergence are iSCSI and FCoE. SCSI doesn’t tolerate failure to deliver the SCSI command very well, so both iSCSI and FCoE have ways to guarantee delivery. With iSCSI, delivery is guaranteed because iSCSI runs on TCP, the reliable Layer 4 protocol. If a lower level frame or packet carrying a TCP segment gets lost, no big deal. TCP using sequence numbers, which are like FedEx tracking numbers, and can re-send a lost segment. So go ahead, WRED, do your worst.
FCoE provides losslessness through priority flow control, which is similar to B2B credits in Fibre Channel. Instead of reserving space on the receiving buffer, PFC keeps track of how full a particular buffer is, the one that’s dedicated to FCoE traffic. If that FCoE buffer gets close to full, the receiving Ethernet port sends a PAUSE MAC control frame to the sending port, and the sending port stops. This is done on a port-per-port basis, so end-to-end FCoE traffic is guaranteed to drive without dropping frames. For this to work though, the Ethernet switches need to speak PFC, and that isn’t part of the regular Ethernet standard, and is instead part of the DCB (Data Center Bridging) set of standards.
Like the shields of the Enterprise, converged networking is in a state of flux. Network administrators and storage administrators are not very happy with the result. Network administrators don’t want storage traffic (and their silly demands for losslessness) on their data networks. St0rage administrators are appalled by Ethernet and it’s devil-may-care attitude towards frames. They’re also not terribly fond of iSCSI, and only grudgingly accepting of FCoE. But convergence is happening, whether they like it or not.
Personally, I’m not invested in any particular technology. I’m a bit more pro-iSCSI than pro-FCoE, but I’m warming to the later (and certainly curious about it).
But given some dyed-in-the-wool network administrators and server administrators are, the biggest problems in convergence won’t be the technology, but instead will be the Layer 8 issues generated. My take is that it’s time to think like a data center administrator, and not a storage or network administrator. However, that will take time. Until then, hilarity ensues.


{kind=link}