Video: Newbie Guide to Python and Network Automation
January 18, 2017 1 Comment
Where servers, storage and networking combine to form Voltron.
January 5, 2017 Leave a comment
This post is inspired by Matt Simmons‘ fantastic post on why we still have ashtrays on airplanes, despite smoking being banned over a decade ago. This time, I’m going to cover seat belts on airplanes. I’ve often heard people balking at the practice for being somewhat arbitrary and useless, much like balking at turning off electronic devices before takeoff. But while some rules in commercial aviation are a bit arbitrary, there is a very good reason for seat belts.

In addition to being a very, very frequent flier (I just hit 1 million miles on United), I’m also a licensed fixed wing pilot and skydiving instructor. Part of the training of any new skydiver is what we call the “pilot briefing”. And as part of that briefing we talk about the FAA rules for seat belts: They should be on for taxi, take-off, and landing. That’s true for commercial flights as well.
Some people balk at the idea of seat belts on commercial airliners. After all, if you fly into the side of a mountain, a seat belt isn’t going to help much. But they’re still important.

In a car, the primary purpose of a seat belt is to protect you from being ejected, and to keep you in one place so the car around you (and airbags) can absorb the impact of an impact. Another purpose, one that is often overlooked, is to keep you from smashing the ever loving shit out of someone who did wear their seat belt.
In skydiving, we have a term that encompasses the kinetic and potential energy contained within the leathery sacks of water and bones known as humans: Meat missiles. Unsecured cargo, including meat missiles, can bounce around the inside of airplanes if there’s a rough landing or turbulence. With all the energy and mass, we can do a lot of damage. That’s why flight attendants and pilots punctuate their “fasten you seat belt” speech with “for your safety and the safety of those around you“.
A lot of people don’t realize that if you don’t wear a seat belt, you’re endangering those around you as much as, or more so, than yourself. Your seat belt doesn’t do much good if a meat missile smashes into you. Check out the GIF below:
http://i.imgur.com/pdrK1Va.gifv
In the GIF, there’s some sort of impact and as a result the unsecured woman on the left smashes into the secured woman on the right. It’s hard to tell how bad they were hurt, though it could have been a lot worse having two heads smash into each other. The side airbag doesn’t do much good if one solid head hits another solid head. Had the woman on the left had her seat belt on it’s likely their injuries would be far less severe.
While incidents in commercial aviation are far more rare than cars, there can be rough landings and turbulence, both expected and unexpected, and even planes colliding while taxing. Those events can cause enough movement to send meat missiles flying, hence the importance of seat belts.
Commercial aviation is probably the safest method of travel, certainly safer than driving. But there is a good reason why we wear seat belts on airplanes.So buckle up, chumps.
May 24, 2016 2 Comments

I’ve seen this misconception a few times on message boards, reddit, and even comments on this blog: That Layer 2 adjacency is no longer required with vSphere 6.0, as VMware now supports Layer 3 vMotion. The (mis)perception is that you no longer need to stretch a Layer 2 domain between ESXi hosts.
That is incorrect. VMware did remove a Layer 2 adjacency requirement for the vMotion Network, but not for the VMs. Lemme explain.
It used to be (before vSphere 6.0) that you were required to have the VMkernel interfaces that performed vMotion on the same subnet. You weren’t supposed to go through a default gateway (though I think you could, it just wasn’t supported). So not only did your VM networks need to be stretched between hosts, but so did your VMkernel interfaces that performed the vMotion sending/receiving.
What vSphere added was a separate TCP/IP stack for vMotion networks, so you could have a specific default gateway for vMotion, allowing your vMotion VMkernel interfaces to be on different subnets.
This does not remove the requirement that the same Layer 2 network exist on the sending and receiving ESXi host. The IP of the VM needs to be the same, so the VM network you vMotion to needs to have the same default gateway (for outbound packets) and inbound routing (for inbound packets).
Inside of a data center this adjacency is typically done by simply making the same VLAN available (natively or now through VXLAN) on all the ESXi hosts in the cluster.
If it’s between datacenter, things tend to get a more complicated. As in dumpster fire. Here’s a presentation I recently did on the topic, and Ivan Pepelnjak has far more high-brow explanations of why it’s a bad idea.
You’ll need solutions like LISP (for inbound), FHRP filtering (for outbound), OTV (for stretching the VLAN), and a whole host of other solutions to handle all the other problems long distance vMotion can introduce.
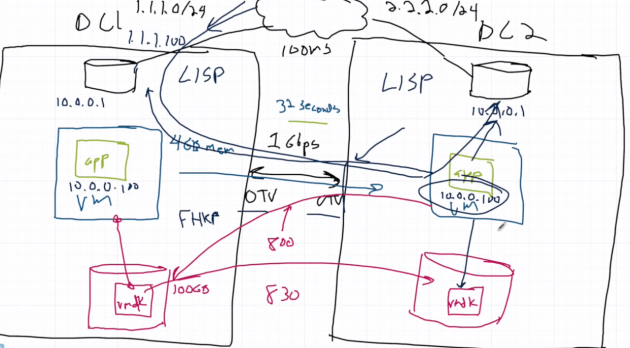
Where is your God now?!?!?
So when you hear that vSphere 6 no longer requires Layer 2 adjacency between ESXi hosts, that’s only for the vmkernel interfaces, not the VM networks. So yes, Virginia, you still need Layer 2 adjacency for vMotion. Even in vSphere 6.0.
April 24, 2016 7 Comments
In this screencast, I go on a rant about why long-distance vMotion is a dumpster fire. Seriously, don’t do it.
April 1, 2016 Leave a comment
Public cloud providers such as Amazon Web Services, Microsoft Azure, and Rackspace, as well as private cloud systems such as OpenStack, have dominated the computing landscape for the past several years. And once a joke of a marketing term (remember Larry Ellison’s super villain-monologue on the topic?), the cloud is now A Thing, with a definition and everything.
One technology that seemed like it was getting left behind in all these cloud games, however, was Fibre Channel. Ephemeral compute nodes, object storage, extreme scale, elastic provisioning — all of these were characteristics that were initially thought to be bad fits for Fibre Channel.

Sad Fibre Channel is Sad
As it turns out, Fibre Channel is right at home in the cloud.

Amazon Web Services has recently rolled out Fibre Channel as a Service (FCaaS), as have Rackspace, Digital Ocean, and Microsoft Azure.
All of those public cloud providers have some sort of block storage offerings, but they’re typically based on something like iSCSI or another back-end block protocol. Customers have been demanding the kind of block storage in the public cloud, where they can control zoning and zonesets, just like they do in their traditional data centers worlds.
The problem with that historically is that AWS and the others haven’t been able to provide this to customers because of the limitations of Fibre Channel at scale. I’ll explain.
Fibre Channel uses FC_IDs, which are like IP addresses, to send Fibre Channel frames around a given SAN. Here’s an FC_ID: 0x510121.
It’s a 24-bit number, typically written in hexadecimal notation. The first octet (two digits) is known as the domain ID. This is given to the switch, so that means there’s a limit of about 240 or so switches in a given fabric (some domain IDs are reserved). Plus, the two vendors of Fibre Channel switches (Brocade and Cisco) limit domain IDs to a maximum of 50 or so, so no more than 50 or so switches for a given fabric.
For a private data center with a single tenant, this isn’t a problem as a 50 switch Fibre Channel fabric is huge. But for Amazon, 50 switches is miniscule.
So enter VXSAN. The SNIA introduced VXSAN recently under the T18 working group, which provides an extension of typical Fibre Channel frame formats. Like VXLAN, VXSAN adds a higher degree of segmentation.
Cisco has VSANs of course, and Brocade has Virtual Fabrics. Neither are compatible with each other, and neither provide the additional scale required to handle massive cloud scale. VXSAN fixes both of those. VXSAN will work on a traditional Fibre Channel SAN from either Brocade or Cisco, without modification through use of the Open Virtual Fibre Channel Switch.
Wait, what?
That’s right, part of any VXSAN implementation is the Open Virtual Fibre Channel Switch (kind of a mouthful, even with the acronym OVFCS).
Similar to how VXLAN operates an overlay network on a traditional IP network as an underlay, VXSAN operates as an overlay SAN on top of a traditional Fibre Channel SAN.
Instead of VTEPs, OVFC switches terminate the VXSAN segments into virtualization hosts and VXSAN aware storage arrays (both EMC and NetApp have them in their latest software revs) to terminate the VXSAN-applied LUN to the a given virtual machine.
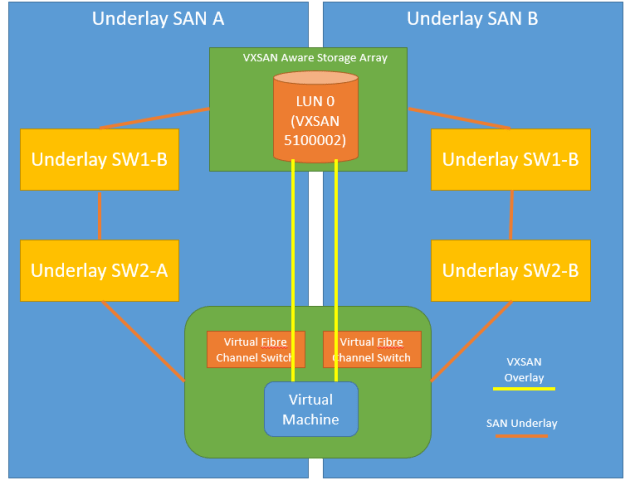
A given virtualization host has two virtual Fibre Channel switches (A/B), each connected to their own Fibre Channel interface (A/B).

The virtual Fibre Channel switches rely on upstream NPIV to get their connectivity, so they can run alongside the hypervisor’s traditional SCSI subsystem. In the example below, both virtual Fibre Channel switches do FLOGIs, as does the hypervisor.

The virtual machines, however, to a vFLOGI into the VXSAN segment, not into the traditional switching infrastructure. The upstream physical switches have no idea a FLOGI happened from the VM.

The VXSAN header, like VXLAN, has a 24-bit address space, providing 16 million segments, each with their own VXSAN fabric capable of having a full Fibre Channel fabric with up to 239 virtual Fibre Channel switches each. So while 239 Fibre Channel switches won’t work for Amazon, 3.8 billion will (16 million x 239).
You will have to enable Fibre Channel jumbo frames on your traditional Fibre Channel fabric, as the VXSAN header adds 62 bytes to the frame format.
VXSAN is designed to run on VXSAN-unaware switches, as it takes for new header formats to make it into silicon, but both Cisco and Brocade have said they plane to release VXSAN-aware switches by the end of the year.
VXSAN is built to be mulit-tenant, so customers from Amazon and others can do their own zoning. I got to play with a Beta of the FCaaS from AWS and I did just a quick configuration with a single VM and a virtual LUN.
First, you log into the A or B virtual Fibre Channel switches. There’s no password, you use the keys you’ve uploaded into Amazon.
Linux Foundation Open Virtual Fibre Channel Switch (Read the Apache 2.0 License for licensing details) switch# switch# config switch#(config) zone Host1 switch(config-zone)# member pwwn 20:00:00:12:34:45:67:aa switch(config-zone)# member pwwn 50:00:00:00:00:ab:cd:ef
I was able to push a zoneset and connected my instance to storage pretty quickly. All in all, it only took about 10 minutes to get it up and running.
OpenStack is prepating to include FCaaS and the Open Virtual Fibre Channel Switch in with the next release (Mikata) due out this month.
So check out FCaaS on Amazon, Azure, and the others. FCaaS should bring Fibre Channel into the cloud world.
Edit: Also, this is an April Fool’s joke. 5 years running.
March 28, 2016 Leave a comment
So there’s a mistake I’ve been making, for years. I’ve referred to what is link aggregation as “LACP”. As in “I’m setting up an LACP between two switches”. While you can certainly set up LACP between to switches, the more correct term for the technology is link aggregation (as defined by the IEEE), and an instance of that is generically called a LAG (Link Aggregation Group). LACP is an optional part of this technology.
Here I am explaining this and more in an 18 minute Youtube video.
January 4, 2016 1 Comment
In my last article, I talked about how Fibre Channel, as a technology, has probably peaked. It’s not dead, but I think we’re seeing the beginning of a slow decline. Fibre Channel’s long goodbye is caused by a number of factors (that mostly aren’t related to Fibre Channel itself), including explosive growth in non-block storage, scale-out storage, and interopability issues.
But rather than diss Fibre Channel, in this article I’m going to talk about the advantages of Fibre Channel has over IP/Ethernet storage (and talk about why the often-talked about advantages aren’t really advantages).
Fibre Channel’s benefits have nothing to do with buffer to buffer credits, the larger MTU (2048 bytes), its speed, or even its lossless nature. Instead, Fibre Channel’s (very legitimate) advantages are mostly non-technical in nature.
When you build a Fibre Channel-based SAN, there’s no optimization that needs to be done: Fibre Channel comes out of the box optimized for storage (SCSI) traffic. There are settings you can tweak, but most of the time there’s nothing that needs to be done other than set port modes and setup zoning. The same is true for the host HBAs. While there are some knobs you can tweak, for the most part the default settings will get you a highly performant storage network.
It’s possible to build an Ethernet network that performs just as well as a Fibre Channel network. It just typically takes more work. You might need to tune MTU (jumbo frames), tune TCP driver settings,tweak flow control settings, or a several other tweaks. And you need someone that knows what all the little nerd-knobs do on IP/Ethernet networks. In Fibre Channel it’s fire and forget.
From host to storage array, Fibre Channel is an air-gapped network in that storage traffic and non-storage traffic would run on completely separate networks. Fibre Channel’s nearly exclusive payload is SCSI, and SCSI as a protocol is far more fragile than other protocols, so running it on a separate network makes sense operationally.
Think about it: If you unplug an Ethernet cable while you’re watching a Youtube video of cats for 5 seconds, and plug it back in, you might see some buffering (and you might not, depending on how much it pre-fetched). If you unplug your hard drive for 5 seconds, well, buffering is going to be the last of your worries.
SCSI is more fragile, so having it on a separate network makes sense.
Ethernet’s strength is that it is supremely flexible. You can run storage traffic on it, video traffic, voice traffic, animated GIFs of cats, etc. You can run iSCSI, HTTP, SMTP, etc. You can run TCP, UDP, IPv4, IPv6, etc. This does add a bit of complication to the configuration of Ethernet/IP networks, however, in the need for tweaking (QoS, flow control, etc.)
Fibre Channel’s strength is that you’re just doing one type of traffic: SCSI (though there is talk of NVMe over Fibre Channel now). Either way, it’s block storage, and that’s all you’re ever going to run on Fibre Channel. This particular characteristic is one of the reasons that Fibre Channel is optimized out of the box.
In IT, we’ve usually been pretty terrified of change. Both in terms of the technology that we’re familiar with, and (more specifically) topological or configuration changes. With DevOps/Agile/whateveryouwanttocallit, the later is changing. But not with Fibre Channel. Fibre Channel configurations are fairly static. And for traditional IT operations, that means a very stable setup. This goes along with the air-gapped network, in that we tend to be much more careful with SCSI traffic.
Fibre Channel has a rather unique solution to network redundancy: Build two completely separate networks: SAN A and SAN B. Fibre Channel’s job is to provide two independent data paths to from the initiator to the target.

From my article Fibre Channel and Ethernet. Also the greatest SAN diagram ever made.
Most of the redundancy in Fibre Channel is instead provided by the host’s drivers (multi-path driver, or MPIO) and in some cases, the storage array’s controller. Network redundancy, beyond having two separate networks, is not required and often not implemented (though available). While Ethernet/IP networks mesh the hell out of everything, in Fibre Channel it’s strictly forbidden to interconnect the A and B fabrics in any way.
A/B network separation wouldn’t work on a global scale of course, but Fibre Channel wasn’t meant to run a global network: Just a local SAN. As a result, it’s a simple (and effective way) to handle redundancy. Plus, it puts the onus on the host and storage arrays, not us SAN administrators. Our responsibility is simple and clear: Two independent data paths.
Another advantage is the centralized configuration for zoning and zonesets with Fibre Channel. You create multiple zones, create a zoneset, and voila, that configuration is automatically pushed out to the other switches in the fabric. That saves a lot of time (and configuration errors) by having one connectivity configuration (zone configuration are what allows which initiators to talk to which targets) that is shared among the switches in a given fabric.
In fact, Fibre Channel provides a whole host of fabric services (name, configuration, etc.) that make management of a SAN easy, even if you’re using the CLI. Both Cisco and Brocade have GUI tools if that’s your thing too (I won’t laugh derisively at you, I promise).
In Ethernet/IP networks, each network device is usually a configuration point itself. As a result, we tend not to use IP access lists for iSCSI or NFS security, instead relying on security mechanisms on the hosts and storage arrays. That’s changing with policy-based Ethernet fabrics (such as Cisco ACI) but for the most part, configuring a storage network based on IP/Ethernet is a bit more of a configuration burden.
Having said all that, there are a few things that I see people point out to as the strengths of Fibre Channel that aren’t really strengths, in that they don’t provide material benefit over other technologies.
Buffer to buffer credits is one of those features. Buffer to buffer credits allows for a lossless fabric overall by preventing frame drop on a port-by-port basis. But buffer to buffer credits aren’t the only way to provide losslessness. iSCSI provides lossless transport by re-transmitting any loss segments. Converged Ethernet (CE) provides losslessness with PFC (priority flow control) sending PAUSE frames to prevent buffer overruns. Both TCP and CE provide the same effect as buffer to buffer credits: Lossless transport.
So if losslessness is your goal, then there’s more than one way to handle that.
Whether its re-transmitting TCP segments, PAUSE frames, or buffer to buffer credits, congestion is congestion. If you try to push 16 Gigabits through an 8 Gigabit link, something has to give.
The only way a buffer can be overfilled is if there’s congestion. Buffer to buffer credits do not eliminate congestion, they’re just a specific way of dealing with it. Congestion is congestion, and the only solution is more bandwidth.

I’ve got congestion, and the only cure is more bandwidth
Buffer to buffer credits, gigantic buffers, flow control, none of these fix bandwidth issues. If you’re starved of bandwidth, add more bandwidth.
While I think the future of storage will be one without Fibre Channel, for traditional workloads (read VMware vSphere), there is no better storage technology in most cases than Fibre Channel. Its strength is not in its underlying technology or engineering, but in its single-minded purpose and simplicity. Most of Fibre Channel’s benefits aren’t even technological: Instead they’re more of a “Layer 8” benefit. And these are the reasons why Fibre Channel, thus far, has been so successful (and nice to work with).
November 23, 2015 8 Comments
There have been several articles talking about the death of Fibre Channel. This isn’t one of them. However, it is an article about “peak Fibre Channel”. I think, as a technology, Fibre Channel is in the process of (if it hasn’t already) peaking.
There’s a lot of technology in IT that doesn’t simply die. Instead, it grows, peaks, then slowly (or perhaps very slowly) fades. Consider Unix/RISC. The Unix/RISC market right now is a caretaker platform. Very few new projects are built on Unix/RISC. Typically a new Unix server is purchased to replace an existing but no-longer-supported Unix server to run an older application that we can’t or won’t move onto a more modern platform. The Unix market has been shrinking for over a decade (2004 was probably the year of Peak Unix), yet the market is still a multi-billion dollar revenue market. It’s just a (slowly) shrinking one.
I think that is what is happening to Fibre Channel, and it may have already started. It will become (or already is) a caretaker platform. It will run the workloads of yesterday (or rather the workloads that were designed yesterday), while the workloads of today and tomorrow have a vastly different set of requirements, and where Fibre Channel doesn’t make as much sense.
Why Fibre Channel Doesn’t Make Sense in the Cloud World
There are a few trends in storage that are working against Fibre Channel:
Cloudy With A Chance of Obsolescence
The transition to cloud-style operations isn’t a great for Fibre Channel. First, we have the public cloud providers: Amazon AWS, Microsoft Azure, Rackspace, Google, etc. They tend not to use much Fibre Channel (if any at all) and rely instead on IP-based storage or other solutions. And what Fibre Channel they might consume, it’s still far fewer ports purchased (HBAs, switches) as workloads migrate to public cloud versus private data centers.
The Ephemeral Data Center
In enterprise datacenters, most operations are what I would call traditional virtualization. And that is dominated by VMware’s vSphere. However, vSphere isn’t a private cloud. According to NIST, to be a private cloud you need to be self service, multi-tenant, programmable, dynamic, and show usage. That ain’t vSphere.
For VMware’s vSphere, I believe Fibre Channel is the hands down best storage platform. vSphere likes very static block storage, and Fibre Channel is great at providing that. Everything is configured by IT staff, a few things are automated though Fibre Channel configurations are still done mostly by hand.
Probably the biggest difference between traditional virtualization (i.e. VMware vSphere) and private cloud is the self-service aspect. This also makes it a very dynamic environment. Developers, DevOpsers, and overall consumers of IT resources configure spin-up and spin-down their own resources. This leads to a very, very dynamic environment.

Endpoints are far more ephemeral, as demonstrated here by Mr Mittens.
Where we used to deal with virtual machines as everlasting constructs (pets), we’re moving to a more ephemeral model (cattle). In Netflix’s infrastructure, the average lifespan of a virtual machine is 36 hours. And compared to virtual machines, containers (such as Docker containers) tend to live for even shorter periods of time. All of this means a very dynamic environment, and that requires self-service portals and automation.
And one thing we’re not used to in the Fibre Channel world is a dynamic environment.
 A SAN administrator at the thought of automated zoning and zonesets
A SAN administrator at the thought of automated zoning and zonesets
Virtual machines will need to attach to block storage on the fly, or they’ll rely on other types of storage, such as container images, retrieved from an object store, and run on a local file system. For these reasons, Fibre Channel is not usually a consideration for Docker, OpenStack (though there is work on Fibre Channel integration), and very dynamic, ephemeral workloads.
Objectification
Block storage isn’t growing, at least not at the pace that object storage is. Object storage is becoming the de-facto way to store the deluge of unstructured data being stored. Object storage consumption is growing at 25% per year according to IDC, while traditional RAID revenues seem to be contracting.
Making it RAIN
In order to handle the immense scale necessary, storage is moving from RAID to RAIN. RAID is of course Redundant Array of Inexpensive Disks, and RAIN is Redundant Array of Inexpensive Nodes. RAID-based storage typically relies on controllers and shelves. This is a scale-up style approach. RAIN is a scale-out approach.
For these huge scale storage requirements, such as Hadoop’s HDFS, Ceph, Swift, ScaleIO, and other RAIN handle the exponential increase in storage requirements better than traditional scale-up storage arrays. And primarily these technologies are using IP connectivity/Ethernet as the node-to-node and node-to-client communication, and not Fibre Channel. Fibre Channel is great for many-to-one communication (many initiators to a few storage arrays) but is not great at many-to-many meshing.
Ethernet and Fibre Channel
It’s been widely regarded in many circles that Fibre Channel is a higher performance protocol than say, iSCSI. That was probably true in the days of 1 Gigabit Ethernet, however these days there’s not much of a difference between IP storage and Fibre Channel in terms of latency and IOPS. Provided you don’t saturate the link (neither handles eliminates congestion issues when you oversaturate a link) they’re about the same, as shown in several tests such as this one from NetApp and VMware.
Fibre Channel is currently at 16 Gigabit per second maximum. Ethernet is 10, 40, and 100, though most server connections are currently at 10 Gigabit, with some storage arrays being 40 Gigabit. Iin 2016 Fibre Channel is coming out with 32 Gigabit Fibre Channel HBAs and switches, and Ethernet is coming out with 25 Gigabit Ethernet interfaces and switches. They both provide nearly identical throughput.
Wait, what?
But isn’t 32 Gigabit Fibre Channel faster than 25 Gigabit Ethernet? Yes, but barely.
Do what now?
32 Gigabit Fibre Channel isn’t really 32 Gigabit Fibre Channel. It actually runs at about 28 Gigabits per second. This is a holdover from the 8/10 encoding in 1/2/4/8 Gigabit FC, where every Gigabit of speed brought 100 MB/s of throughput (instead of 125 MB/s like in 1 Gigabit Ethernet). When FC switched to 64/66 encoding for 16 Gigabit FC, they kept the 100 MB/s per gigabit, and as such lowered the speed (16 Gigabit FC is really 14 Gigabit FC). This concept is outlined here in this screencast I did a while back. 16 Gigabit Fibre Channel is really 14 Gigabit Fibre Channel. 32 Gigabit Fibre Channel is 28 Gigabit Fibre Channel.
As a result, 32 Gigabit Fibre Channel is only about 2% faster than 25 Gigabit Ethernet. 128 Gigabit Fibre Channel (12800 MB/s) is only 2% faster than 100 Gigabit Ethernet (12500 MB/s).
Ethernet/IP Is More Flexible
In the world of bare metal server to storage array, and virtualization hosts to storage array, Fibre Channel had a lot of advantages over Ethernet/IP. These advantages included a fairly easy to learn distributed access control system, a purpose-built network designed exclusively to carry storage traffic, and a separately operated fabric. But those advantages are turning into disadvantages in a more dynamic and scaled-out environment.
In terms of scaling, Fibre Channel has limits on how big a fabric can get. Typically it’s around 50 switches and a couple thousand endpoints. The theoretical maximums are higher (based on the 24-bit FC_ID address space) but both Brocade and Cisco have practical limits that are much lower. For the current (or past) generations of workloads, this wasn’t a big deal. Typically endpoints numbered in the dozens or possibly hundreds for the large scale deployments. With a large OpenStack deployment, it’s not unusual to have tens of thousands of virtual machines in a large OpenStack environment, and if those virtual machines need access to block storage, Fibre Channel probably isn’t the best choice. It’s going to be iSCSI or NFS. Plus, you can run it all on a good Ethernet fabric, so why spend money on extra Fibre Channel switches when you can run it all on IP? And IP/Ethernet fabrics scale far beyond Fibre Channel fabrics.
Another issue is that Fibre Channel doesn’t play well with others. There’s only two vendors that make Fibre Channel switches today, Cisco and Brocade (if you have a Fibre Channel switch that says another vendor made it, such as IBM, it’s actually a re-badged Brocade). There are ways around it in some cases (NPIV), though you still can’t mesh two vendor fabrics reliably.

Pictured: Fibre Channel Interoperability Mode
And personally, one of my biggest pet peeves regarding Fibre Channel is the lack of ability to create a LAG to a host. There’s no way to bond several links together to a host. It’s all individual links, which requires special configurations to make a storage array with many interfaces utilize them all (essentially you zone certain hosts).
None of these are issues with Ethernet. Ethernet vendors (for the most part) play well with others. You can build an Ethernet Layer 2 or Layer 3 fabric with multiple vendors, there are plenty of vendors that make a variety of Ethernet switches, and you can easily create a LAG/MCLAG to a host.

My name is MCLAG and my flows be distributed by a deterministic hash of a header value or combination of header values.
What About FCoE?
FCoE will share the fate of Fibre Channel. It has the same scaling, multi-node communication, multi-vendor interoperability, and dynamism problems as native Fibre Channel. Multi-hop FCoE never really caught on, as it didn’t end up being less expensive than Fibre Channel, and it tended to complicate operations, not simplify them. Single-hop/End-host FCoE, like the type used in Cisco’s popular UCS server system, will continue to be used in environments where blades need Fibre Channel connectivity. But again, I think that need has peaked, or will peak shortly.
Fibre Channel isn’t going anywhere anytime soon, just like Unix servers can still be found in many datacenters. But I think we’ve just about hit the peak. The workload requirements have shifted. It’s my belief that for the current/older generation of workloads (bare metal, traditional/pet virtualization), Fibre Channel is the best platform. But as we transition to the next generation of platforms and applications, the needs have changed and they don’t align very well with Fibre Channel’s strengths.
It’s an IP world now. We’re just forwarding packets in it.
September 1, 2015 1 Comment
Here’s a quick whiteboard session of the differences between traditional and cloud native web applications.
June 23, 2015 Leave a comment
In the networking world, we’re starting to see the term “cloud” more and more. When I teach classes, if I so much as mention the word cloud, I start to see some eyes roll. That’s completely understandable, as the term cloud was such an overused buzzword, only having been recently supplanted only by “software defined”.
Here’s real-life supervillain (dude owns an MiG 29 and an island with a volcano on it… seriously) Larry Ellison freaking out about the term cloud.
“It’s not water vapor! All it is, is a computer attached to a network!”
But here’s the thing, it’s actually a thing now. Rather than a catch-all buzzword, it’s being used more and more to define a particular type of operational model. And it’s defined by NIST, the National Institute of Standards and Technology, part of the US Department of Commerce. With the term cloud, we now get a higher degree of specificity.
The NIST definition of cloud is as follows:
That first item on the list, the on-demand self service, is a huge change in how we will be doing networking. Right now network configurations are mostly done by network administrators. If you have a network need and aren’t a network admin, you open up a ticket and wait.
In (private) cloud computing, which will include a large networking component, the network elements, end points, and devices will be configured by end-users/developers, not the IT staff. The IT staff will maintain the overall cloud infrastructure, but will not do the day-to-day changes. The changes will happen far too frequently, and they will happen in the middle of the day. Change control will probably be handled for the underlying infrastructure, but the tenants will likely make many changes during the day. The fault domains will be a lot smaller, making mistakes impactful to a small segment for these changes, and the automation will make chance that a change (such as adding a new load balancing VIP) will be done correctly much higher.
This is how things have been done in public clouds (Amazon, Rackspace, etc.) for a while now.
When people talk about the death of the CLI, this is what they’re referring to. The configuration changes we make won’t be on a Cisco or Juniper CLI, but through some sort of portal (which can be either GUI, CLI, or API calls) and will be largely automated. We’ve hit the twilight of the age of Conf T.
With OpenStack, Docker, CoreOS, containers, DevOps, ACI, NSX, and all of the new operational models, technologies, and platforms, the next generation data center will be a self-service data center.
