Ethernet over Fibre Channel
April 1, 2015 11 Comments
Since the 80’s, Ethernet has dominated the networking world. The LAN, the WAN, and the MAN are all now dominated by Ethernet links. FIDDI, HIPPI, ATM, Frame Relay, they’ve all gone by the wayside. But there is one protocol that has stuck around to run alongside Ethernet, and that’s Fibre Channel. While Fibre Channel has mostly sat in the shadow of Ethernet, relegated to only storage traffic, it’s now poised to overtake Ethernet in the battle for the LAN. And the way that Fibre Channel is taking on Ethernet is with Ethernet over Fibre Channel.

Suck it, Metcalfe
While Ethernet has enjoyed tremendous popularity, it has several (debilitating) limitations. For one, forwarding is haunted the possibility of a loop, and Spanning Tree Protocol is required to keep a watchful eye. Unfortunately, STP is almost as bad as a loop, with the ample opportunity for misconfigurations (rouge root bridges) and other shenanigans. TRILL, a Layer 2 overlay for Ethernet that allows multi-pathing, hasn’t found its way into a commercial product yet, and its derivatives (FabricPath from Cisco and VCS from Brocade) haven’t seen much in the way of adoption.
Rathern than pile fix upon fix on Ethernet, SAN administrators (known for being the loose canons of the data center) are making a bold push to take over LAN networks as well… and they’re winning.
The T17 committe had been established by the INCITS, which is the standards body that is responsible for Fibre Channel, FCoE, and now EoFC. The T17 is responsible for all the specifications around EoFC, and in particular the interface between the two.
“We really have a lot of advantages over Ethernet in terms of topology and forwarding. For one, we’re a lossless network, providing a lot more reliability than a traditional Ethernet network. We also have multi-pathing built in with FSPF routing, while still providing Layer 2 adjacencies that are still required by the old crusty crapplications that are still on people’s networks, somehow.” -John Etherman, T17 committee chair.
They’ve made a lot of progress in a relatively short time, from ironing out the specifications to getting ASICs spun, and their work is bearing fruit. Products are starting to ship, and several marquee clients have announced fabrics built entirely with EoFC.
A Day in the life of a EoFC Frame
To keep compatibility with older Ethernet/TCP/IP stacks, CNHs (Converged Network HBAs) provide Ethernet interfaces to the host operating system. The frame is formed by the host, and the CNH encapsulates the Ethernet frame into a Fibre Channel frame. Since standard Ethernet MTU is only 1500 bytes, they fit quite nicely into the maximum 2048 byte Fibre Channel frame. The T13 working group also provides specifications for Jumbo Ethernet frames up to 9216 bytes, by either fragmenting the frame into multiple 2048-byte Fibre Channel frames,
WWPNs are derived from the MAC addresses that the hosts sees. Since MAC addresses aren’t a full 64-bits, the T17 working group has allocated the 80:08 prefix to EoFC. So if your MAC address was 00:25:B6:01:23:45, the WWPN would be 80:08:00:25:B6:01:23:45. This keeps the EoFC WWPNs out of the range of the initiators (starting with 1 or 2) and targets (starting with 5).
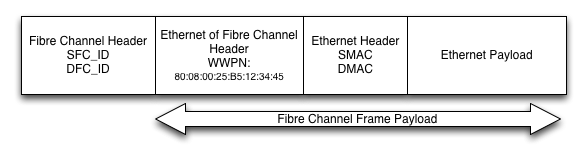
FC_IDs are assigned to the WWPNs on a transitory basis, and are what the Fibre Channel headers have in terms of source/destination addresses. When the Fibre Channel frame reaches its destination NX_Port (Node LAN port), the Ethernet frame is de-encapsulated from the Fibre Channel frame, and the hosts networking stack takes care of the rest. From a host’s perspective, it has no idea the transport is Fibre Channel.
Reliability
The biggest benefit to EoFC is the lossless network that Fibre Channel provides. Since the majority of traffic is East/West in modern data center workloads, busy hosts can suffer from an incast problem, where the buffers can be overloaded as a single 10 Gigabit link receives packets from multiple sources, all operating at 10 Gigabit. Fibre Channel transport provides port to port flow control, and can ensure that nothing gets dropped.
Configuration
Configuration of EoFC is fairly straightforward. I’ve got access to a new Nexus 8008, with a 32 Gbit EoFC line card that I’ve connected to a Cisco C-series server with a CNH.
nexus1# feature eofc EoFC feature checked out Loading Ethernet module... Loading Spanning Tree module... Loading LLDP... Grace period license remaining: 110 days nexus1# vlan 10 nexus1(vlandb)# vsan 10 nexus1(vsandb)# 10 name Storage-A nexus1(vsandb)# vsan 1010 nexus1(vsandb)# vsan 1010 name Ethernet transport nexus1(vsandb)# eofc vlan 10 nexus1(vsandb)# interface veth1 nexus1(vif)# switchport nexus1(vif)# switchport mode access nexus1(vif)# switchport access vlan 10 nexus1(vif)# bind interface fc1/1 nexus1(vif)# no shut nexus1(vif)# int fc1/1 nexus1(if)# switchport mode F nexus1(if)# switchport allowed vsan 10,1010 nexus1(if)# no shut
Doing a show interface shows me that my connection is live.
nexus1# show interface ethernet veth1 vEthernet1 is up Hardware: 1000/10000 Ethernet, address: 000d.ece7.df48 (bia 000d.ece7.df48) Attached to: fc1/1 (pWWN: 80:08:00:0D:EC:E7:DF:48) MTU 1500 bytes, BW 10000000 Kbit, DLY 10 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation EoFC/ARPA Port mode is EoFC full-duplex, 32 Gb/s, media type is 1/2/4/8/16/32g Beacon is turned off Input flow-control is off, output flow-control is off Rate mode is dedicated Switchport monitor is off Last link flapped 09:03:57 Last clearing of "show interface" counters never 30 seconds input rate 2376 bits/sec, 0 packets/sec 30 seconds output rate 1584 bits/sec, 0 packets/sec Load-Interval #2: 5 minute (300 seconds) input rate 1.58 Kbps, 0 pps; output rate 792 bps, 0 pps RX 0 unicast packets 10440 multicast packets 0 broadcast packets 10440 input packets 11108120 bytes 0 jumbo packets 0 storm suppression packets 0 runts 0 giants 0 CRC 0 no buffer 0 input error 0 short frame 0 overrun 0 underrun 0 ignored 0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop 0 input with dribble 0 input discard 0 Rx pause TX 0 unicast packets 20241 multicast packets 105 broadcast packets 20346 output packets 7633280 bytes 0 jumbo packets 0 output errors 0 collision 0 deferred 0 late collision 0 lost carrier 0 no carrier 0 babble 0 Tx pause 1 interface resets switch#
Speeds and Feeds
EoFC is backwards compatible with 1/2/4/8 and 16 Gigabit Fibre Channel, but it’s really expected to take off with the newest 32/128 Gbit interfaces that are being released from vendors like Cisco, Juniper, and Brocade. Brocade, QLogix, Intel, and Emulex are all expected to provide CNHs operating at 32 Gbit speeds, with 32 and 128 Gbit interfaces on line cards and fixed switches to operate as ISLs.

Nexus 8008: 384 ports of 32 Gbit EoFC
Switches are already shipping from Cisco and Brocade, with Juniper to release their newest QFC line before the end of Q2.